Webアクセスロボット
目次
-
-
- 1.Webアクセスロボット
- 1.1 WARの概要
- 1.2 WARの特徴
- 1.3 WARの製品利用例
- 1.4 WARの機能
-
- 1.4.1 自動アクセス機能
- 1.4.2 改ざんチェック機能
- 1.5 WARの設定
-
- 1.5.1 画面メニューからの設定
- 1.5.2 WAR.INIの設定
- 1.7 WARのFAQ
- 付録
- 付録A.用語集
WARはロボットです。ISMを介すことにより、Webブラウザを使わずにインターネット上のWebページ(HTMLファイル)や画像、音楽などのファイルを自動的に収集することができます。収集したHTMLファイルのハイパーリンク先を辿って、芋づる式に次々に該当するページや画像などのファイルも取得することもできます。また、Webページの改ざんをチェックする機能もありますので、例えば、WARを実行してWebページが変更されていないかをチェックしたり、あるいはハッカーなどがWebページを改ざんしていないかをチェックするといった使い方ができます。
このロボットを使えば、例えば通信料が安い時間帯やWebアクセスが少ない時間帯を利用して、設定したHTMLファイルからのハイパーリンクのファイルを全て自動的に取得することができますので、パソコンの前に座っておく必要はありませんし、時間も気にする必要はありません。取得した情報はISMによってローカルのパソコンにファイルとして全てキャッシュされています。WPMによってハイパーリンクを自動調整すれば、オフラインにして通信料を気にせず、後でゆっくりローカルのファイルを閲覧することができます。
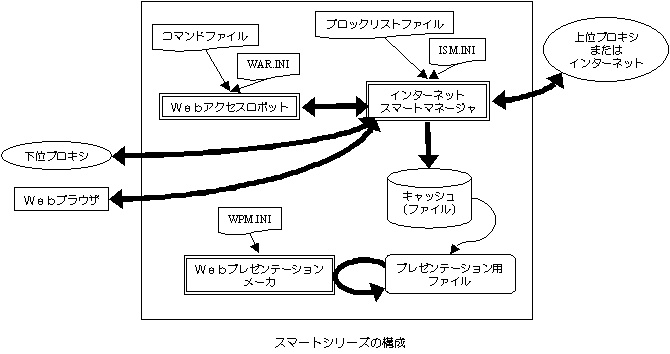
WARはISMをプロキシーとして動作するロボットです。WARの主な動きとしては以下のようになります。
- ユーザが指定したコマンドファイルを解析し、指示されたURLにISMを介してアクセスする。
- アクセスの結果、取得されたファイルがHTMLファイルである場合は、そのソースを解析し、ハイパーリンクを探す。
- ユーザが指定したファイル種別、深さ、あるいはドメインの範囲内であるならば、そのハイパーリンクに再びアクセスする。
- これを繰り返す。
-
- WARのインストールは、非常に簡単です。
-
- レジストリを使いませんので、インストール、アンインストールも、非常に簡単です。
-
- アクセスするURLの複数指定
-
- WARの制御情報(コマンドファイル、またはアクセス条件を意味します)には自動的にアクセスさせるURLを複数指定することができます。またコマンドファイルは複数作成することもできますから、例えば趣味に関するURL、仕事に関するURLなどのグループ化を行い、管理することもできます。
-
- リンクを辿って自動アクセス
-
- WARは、最初に読み込んだHTMLファイルのリンクタグを辿ることにより、下の階層、あるいはリンク先の別のサイトへと次々と辿って自動アクセスすることができます。また、階層については何階層かといった指定、あるいは同一サイト内以外はアクセスしないなどの条件も指定することができます。
-
- 範囲指定が可能
-
- WARの制御情報の指定には、アクセスするファイルの範囲などを指定することができます。例えば、画像ファイルの数値が連続したようなファイルがあることが予め分かっているサイトにアクセスするような場合、次の様に指定すると、連続して50個のjpeg画像をアクセスすることができます。
「http://www.nasa.gov/HST/ Galaxy001.jpg →50.jpg」
この"→"は2バイトコードの矢印ですが、1バイトコードの"->"でも記述することができます。
-
- 時刻指定が可能
-
- WARを起動する時刻を指定することができます。例えば、電話料金の安い時間帯や、ネットワークの負荷の少ない時間帯にアクセスすることができたり、あるいは、ページ更新チェックの機能と一緒に使うことにより、技術情報に関するページを毎朝チェックし、更新されているか否かを自動的にチェックすることができます。
-
- 中断と再開が可能
-
- WARが自動的にロボットとしての行動(自動アクセス)を行っている最中、区切りの良い所で中断することができます。ロボットがきちんと動作しているか、最初の段階で中断させて、ISMのキャッシュを確認することができます。また、その後「開始」を行うと、中断していた後から継続して再開することができますので、無駄がありません。
-
- ページ更新チェックが可能
-
- 指定したWebページの内容が更新されているかがチェックできます。これにより、人の目で更新されていないか、毎日チェックするといった手間がなくなります。
1) アクセスしたWebページを、後で、電話代やISPの接続料を気にせずに読むことができ、電話代やISPの接続料を節約できます。
2) 或るWebページが変更されているか自動的にチェックし、変更されていることを自動的に知ることができます。
3) 電話料金の安い時間帯や、ネットワークの負荷の少ない時間帯にアクセスすることができ、結果的に、電話代やISPの接続料を節約できます。
4) 人間の操作が必要無いので、パソコンの前に座ってWebブラウザを操作し続ける必要もなく、効率的にアクセスすることができます。
-
- WARはロボットです。WARにコマンドファイルで指示をすることにより、WARはISMを介して(Webブラウザを使わずに)自動的にインターネット上のWebページ(HTMLファイル)や画像、音楽などのファイルを自動的に収集してまわります。コマンドファイルの指定によっては、収集したHTMLファイルのハイパーリンク先を辿って、芋づる式に次々に該当するページや画像などのファイルも取得することができます。コマンドファイルの指定方法はWARの「自動アクセス開始指示」メニューから指示することもできます。コマンドファイルの具体的な説明は、以下のとおりです。
-
-
- コマンドファイルは、WARに動作指示をする為のファイルです。コマンドファイルは、WARプログラムと同じディレクトリの中に存在しなければならず、また、コマンドファイルの名前は固定で、常に次の名前のファイルでなければなりません。
-
- 「robotcommand.txt」
- WARは、起動されると、コマンドファイルが存在するか否かチェックし、コマンドファイルが、存在するならば、そのコマンドファイルの内容を、WARの制御ウィンドウの中に表示します。コマンドファイルが、存在しない場合、WARは、「コマンドファイルが見つからない旨」の警告メッセージを表示した後、空のWARの制御ウィンドウを表示します。
- コマンドファイルとWARの制御ウィンドウとは連動しており、WARの制御ウィンドウの内容が追加や、変更された場合、その変更はコマンドファイルに反映されます。
-
-
- コマンドファイル中で使われるステートメントには、以下のものがあります。
- (A)空白行
-
- 意味の無い行と見なし、無視します。
- (B) #mode=limited
-
- ドメイン名限定のアクセスを指示します。この場合、「http://」または、「https://」ステートメントで指示されるドメイン名のデータのみをアクセスします。「#maxlevel=」ステートメントで、最大アクセス階層が、指定されていない場合、1024階層まで、アクセスします。
-
| コマンドファイルの記述例 | 説明 |
#mode=limited
http://www.mpt.go.jp/joho_tsusin.html |
当該ページからリンクされているドメイン名www.mpt.go.jpのデータのみをアクセスします。 |
- (C) #mode=limited ドメイン名
-
- 「#mode=limited」ステートメントと似ていますが、アクセスを限定するドメイン名を明示的に指定する点が、異なります。
-
| コマンドファイルの記述例 | 説明 |
#mode=limited www.soumu.go.jp
http://www.mpt.go.jp/joho_tsusin.html |
当該ページからリンクされているドメイン名www.soumu.go.jpのデータのみをアクセスします。 |
#mode=limited www.
http://www.mpt.go.jp/joho_tsusin.html |
部分指定も可能です。当該ページからリンクされているドメイン名にwww.を持つドメインのデータのみをアクセスします。すなわち、www.mpt.go.jpのデータも、www.soumu.go.jpのデータもアクセスします。。 |
#mode=limited www.mpt.go.jp/joho
http://www.mpt.go.jp/joho_tsusin.html |
ディレクトリ名指定やデータ名指定もできます。当該ページからリンクされているWebページで、そのURLの先頭がwww.mpt.go.jp/johoのデータのみをアクセスします。
【注】マスク指定はできません。 |
- (D) #mode=unlimited
-
- ドメイン名限定のアクセスを解除します。
- (E) #mode=noreferer
-
- referrer(リファラー:参照者)無しでアクセスすることを指示します。リファラーは、HTTPヘッダーに含まれる情報で、リンク元ページが何かを示します。
- (F) #mode=referrer
-
- referrer(リファラー:参照者)付きで、アクセスすることを指示します。WARの場合、リファラーは、常に、アクセスするサイトのドメイン名になります。
- (G) #mode=norobot
-
- Webページの中に次のようなロボット用METAタグが設定されている事があります。
<META name="ROBOTS" content="NOINDEX, NOFOLLOW">
主に検索ロボットに対する指示で、上記のように記述されているMETAタグを発見した場合には,そのページをサーチエンジンに登録しませんし (NOINDEX),そのページに含まれているリンクをたどりません(NOFOLLOW)。このステートメントは、WARが、ロボット用METAタグに従うか否かの指定で、このステートメントを指定するとロボット用METAタグに従いません。
- (H) #mode=robot
-
- このステートメントを指定すると、WARは、ロボット用METAタグに従います。
【注】ロボット用METAタグと類似のものに、robots.txtファイルがありますが、WARはrobots.txtの処理は行いません。
- (I) #mode=tampercheck
-
- WARを「Webページ改ざんチェックモード」で、動作させることを指示します。
#mode=tampercheck指定を行う場合、改ざんチェックの基準データの場所が予め指定されていなければなりません。
改ざんチェックの基準データの場所が指定されて無いのに、#mode=tampercheck指定を行った場合、そのステートメントは無視されます。
改ざんチェックの基準データの場所指定は、WAR.INIファイルの「originaldatadir=」ステートメント又は、WARの画面上のメニューを用いて指定することが、できます。WARは、「Webページ改ざんチェックモード」の場合、アクセスしたデータと、基準データとを比較しながら自動アクセスを行い、データのサイズが異なるか、新らたに作られたデータを発見した場合、変更ログファイルにそのWebページのURLを出力します。
- (J) #mode=notampercheck
-
- WARを「非Webページ改ざんチェックモード」で動作させることを指示します。
- (K) #maxlevel=
-
- WARが自動アクセスする最大リンク階層数を1から255の範囲の数字で指定します。WARに明示的に指定されたWebページのリンク階層数は「0」で、そのページからリンクされたWebページのリンク階層は「1」とカウントされます。既定値は「1」です。
- (L) #
-
- 上記ステートメント以外の#で始まる行は、コメント行となります。
- (M) //
-
- //で始まる行は、コメント行となります。
- (N) http://
-
- WARに対するアクセス指示です。次の二つの指示タイプがあります。
- (1) 単一指定タイプ
-
- WARに指定されたURLのWebページをアクセスするよう指示します。WARは、当該Webページと、そのページからリンクされているWebページをアクセスします。
次の形式で指定します。
・http://URL
| コマンドファイルの記述例 | 説明 |
| http://www.jpcert.or.jp/ |
ドメイン名「http://www.jpcert.or.jp/」のデータをアクセスします。 |
| http://www.stsci.edu/PR/34/content/0034w.jpg |
0034w.jpgのデータをアクセスします。 |
- (2) 範囲指定タイプ
-
- WARに指示したURLの数字部分を変化させ、指定された範囲のURLを連続的にアクセスするよう指示します。
次の形式で指定します。
・「http://……開始数文字列……[空白1文字][範囲指定文字][終了文字列]
【注】下記の例のURLのページは、アクセスできるとは限りません。
| コマンドファイルの記述例 | 説明 |
| http://www.stsci.edu/pub/pr/95/01.html →04.htm |
この場合、WARは、次の4つのWebページを次の順番でアクセスします。
・http://www.stsci.edu/pub/pr/95/01.html
・http://www.stsci.edu/pub/pr/95/02.html
・http://www.stsci.edu/pub/pr/95/03.html
・http://www.stsci.edu/pub/pr/95/04.html |
| http://www.stsci.edu/pub/pr/95/01.html ->04.htm |
上記の例と同じです。 |
| http://www.stsci.edu/pub/pr/95/01.html 〜04.htm |
上記の例と同じです。 |
| http://www.stsci.edu/pub/pr/95/04.html →01.htm |
この場合、WARは、次の4つのWebページを次の順番でアクセスします。
・http://www.stsci.edu/pub/pr/95/04.html
・http://www.stsci.edu/pub/pr/95/03.html
・http://www.stsci.edu/pub/pr/95/02.html
・http://www.stsci.edu/pub/pr/95/01.html |
| http://www.stsci.edu/pub/pr/95/01.html →96/ |
この場合、WARは、次のWebページを次の順番でアクセスします。
・http://www.stsci.edu/pub/pr/95/01.html
・http://www.stsci.edu/pub/pr/96/01.html |
範囲指定文字として次の文字を使うことができます。開始文字列と終了文字列とに数字以外の文字を指定することができますが、数字でない文字は同一でなければなりません。数字は、昇順、降順のどちらでも指定できます。
-
-
| 範囲指定文字 | 説明 |
| -> | ANKの-(ハイフン)と>(左大) |
| → | 2バイトコードの右矢印 |
| 〜 | 2バイトコードの波線 |
- (O) https://
-
- WARに対するアクセス指示です。その指定規則は、上記の「http://」と同一で、「http://」が、「https://」となる部分のみが異なります。
- (P) 済
-
- WARが、正常にアクセスを完了した指示であることを示します。次回WARが実行する際には、この行をコメントとして処理します。
- (Q) 上記以外
-
- WARに、どの情報をアクセスし、また、他のどの情報をアクセスしないかを指定します。指定規則は、ISMのブロックファイルの指定と同様に次のようになります。なお、「回避指定」と「アクセスする指定」との両方の対象となる場合は、「アクセスする指定」が優先します。
- (1)指定サイトの情報をアクセス回避
-
| [指定例] |
| www.xxx.yy.zz | www.xxx.yy.zzの名前のサイトの情報をアクセス回避 |
| cy*.*.*.* | cyで始まる名前のサイトの情報をアクセス回避 |
| *.*.*.jp | 最後が.jpの名前のサイトの情報をアクセス回避 |
(2)指定ディレクトリの情報をアクセス回避
-
| [指定例] |
| /xxx/ | /xxx/の名前のディレクトリの情報をアクセス回避 |
| /xxx/yy/zz/ | /xxx/yy/zz/の名前のディレクトリの情報をアクセス回避 |
| /*.*/ad/ | 第二階層目にadの名前を持つディレクトリの情報をアクセス回避 |
(3)指定タイプの情報をアクセス回避
-
| [指定例] |
| /virus.exe | virus.exeの名前を持つ情報をアクセス回避 |
| /*.exe | 拡張子が.exeの情報をアクセス回避 |
| /*.gif | 拡張子が.gifの情報をアクセス回避 |
(4)組み合わせ条件(1)〜(3)の情報をアクセス回避
-
| [指定例] |
| www.xxx.yy.zz/xxx/ | www.xxx.yy.zzの名前のサイト中の/xxx/の名前のディレクトリの情報をアクセス回避 |
| www.xxx.yy.zz/*.*/ad | www.xxx.yy.zzの名前のサイト中の第二階層目にadの名前を持つディレクトリの情報をアクセス回避 |
| *.*.*.jp/*.*/ad/*.gif | 最後が.jpの名前のサイト中の第二階層目にadの名前を持つディレクトリに存在する拡張子が.gifの情報をアクセス回避 |
(5)指定サイトの情報をアクセスする:(1)の指定形式の先頭に~を付加することで指定します。
-
| [指定例] |
| ~www.xxx.yy.zz | www.xxx.yy.zzの名前のサイトの情報をアクセスする |
| ~cy*.*.*.* | cyで始まる名前のサイトの情報をアクセスする |
| ~*.*.*.jp | 最後が.jpの名前のサイトの情報をアクセスする |
(6)指定ディレクトリの情報をアクセスする:(2)の指定形式の先頭に~を付加することで指定します。
-
| [指定例] |
| ~/xxx/ | /xxx/の名前のディレクトリの情報をアクセスする |
| ~/xxx/yy/zz/ | /xxx/yy/zz/の名前のディレクトリの情報をアクセスする |
| ~/*.*/ad/ | 第二階層目にadの名前を持つディレクトリの情報をアクセスする |
(7)指定タイプの情報をアクセスする:(3)の指定形式の先頭に~を付加することで指定します。
-
| [指定例] |
| ~/virus.exe | virus.exeの名前を持つ情報をアクセスする |
| ~/*.exe | 拡張子が.exeの情報をアクセスする |
| ~/*.gif | 拡張子が.gifの情報をアクセスする |
(8)組み合わせ条件(5)〜(7)の情報をアクセスする:(4)の指定形式の先頭に~を付加することで指定します。
-
| [指定例] |
| ~www.xxx.yy.zz/xxx/ | www.xxx.yy.zzの名前のサイト中の/xxx/の名前のディレクトリの情報をアクセスする |
| ~www.xxx.yy.zz/*.*/ad | www.xxx.yy.zzの名前のサイト中の第二階層目にadの名前を持つディレクトリの情報をアクセスする |
| ~*.*.*.jp/*.*/ad/*.gif | 最後が.jpの名前のサイト中の第二階層目にadの名前を持つディレクトリに存在する拡張子が.gifの情報をアクセスする |
-
- WARはインターネット上のWebページの内容が変更されたことを調べる機能もあります。以前アクセスしたWebページの内容(ディレクトリ)を画面メニューの「改ざんチェックの基準データの場所指定」か、WAR.INIの「OriginalDataDir=」ステートメントで指定します。WARは、「Webページ改ざんチェックモード」の場合、アクセスしたデータと基準データとを比較しながら自動アクセスを行い、データのサイズが異なるか、新らたに作られたデータを発見した場合、変更ログファイルにそのWebページのURLを出力します。
例えば複数の趣味WebページのURLをチェックしたとき、「状態表示」ビューでWebページの更新が確認されたものだけ、ISMがキャッシュした内容を読む、といった使い方ができます。既に読んだ内容か、更新された内容かを一目で確認することができますので、従来のように、変更があったか否かをWebページを読むことにより確認する必要がなくなります。
この機能を使う場合は、コマンドファイルにおいて「#mode=tampercheck」と指定します。コマンドファイルの記述については、コマンドファイルの記述方法を参照してください。
WAR(WebAccessRobot.exe)をダブルクリックなどで起動すると、WARの画面が表示されます。WARの画面メニューで指定可能な機能は以下のとおりです。
WARの画面メニュー
- 終了指示
- 指令に関する操作
- 自動アクセス開始指示
- 停止指示
- プログラム情報
- ヘルプ
WARの画面メニューで指定可能な機能は、以下の通りです。WAR.INIの設定も参照してください。
-
- 「終了指示」
-
- 終了指示項目で終了を指示することで、ISMを終了させることができます。
終了を指示すると、終了確認のメッセージが表示され、そのメッセージに「はい」を応答するとISMが終了します。それに対し、「いいえ」を応答すると、終了指示を取り消すことができます。
-
- 「指令に関する操作」
-
- WARに設定した自動アクセスの指令に関する情報、あるいはWAR自体の設定を行うことができます。
-
- (1)変更した制御情報の保存
-
- WARの現在の制御情報(コマンドファイル、またはアクセス条件を意味します)を保存します。制御情報を保存するファイル名の規定値は「robotcommand.txt」です。WARを終了させるときにも現在の情報を保存しますが、この「変更した制御情報の保存」機能により、例えばWARを終了させずに、「制御ファイルの変更」(コマンドファイルの変更)をしながら、次々に制御情報を作ることができます。保存した情報は次回、WARを起動したときに自動的に読み込みます。
- (2)リンク情報の表示
-
- WARが制御情報(コマンドファイル、またはアクセス条件を意味します)に基づきアクセスしたURLのリンク情報を表示します。この機能は「指示情報」ビューを変更しますので、本の制御情報に戻す場合は「制御情報の再表示」を行ってください。
- (3)制御情報の再表示
-
- WARの現在の制御情報(コマンドファイルの中身、またはアクセス条件を意味します)を表示します。「リンク情報の表示」や「開始」などで変更された「指示情報」ビューの表示を、制御情報が保存されたファイルから読み込み直すことにより、元の状態に戻すことができます。例えばWARを「開始」した後はアクセスしたURL(http://〜)の左に「済」という文字が表示されますが、この再表示機能を実行することにより、WARの状態を戻し、再度「開始」を行うことができます。制御情報を保存するファイル名の規定値は「robotcommand.txt」ですが、「制御ファイルの変更」(コマンドファイルの変更)で変更することができます。
- (4)制御ファイルの変更(コマンドファイルの変更)
-
- WARの現在の制御情報(アクセス条件)を保存するコマンドファイル名を指定します。制御情報を保存するファイル名の規定値は「robotcommand.txt」です。例えば絶対ディレクトリ(c:\command.txtなど)を指定することもできます。制御情報(アクセス条件)を保存するファイルの内容についての説明は、WAR.INIの設定を参照してください。
- (5)改ざんチェックの基準データの場所指定
-
- WARはインターネット上のWebページの内容が変更されたことを調べる機能もあります。以前アクセスしたWebページの内容(ディレクトリ)を画面メニューの「改ざんチェックの基準データの場所指定」か、WAR.INIの「OriginalDataDir=」ステートメントで指定します。WARは、「Webページ改ざんチェックモード」の場合、アクセスしたデータと基準データとを比較しながら自動アクセスを行い、データのサイズが異なるか、新らたに作られたデータを発見した場合、変更ログファイルにそのWebページのURLを出力します。
詳しくは、改ざんチェック機能を参照してください。
-
- 「自動アクセス開始指示」
-
- WARが自動的にアクセスする条件の指定と、自動アクセスの開始指示ができます。
-
- (1)アクセス条件の追加
-
- WARの現在の制御情報(コマンドファイル、またはアクセス条件を意味します)を保存します。制御情報を保存するファイル名の規定値は「robotcommand.txt」です。WARを終了させるときにも現在の情報を保存しますが、この「変更した制御情報の保存」機能により、例えばWARを終了させずに、「制御ファイルの変更」(コマンドファイルの変更)をしながら、次々に制御情報を作ることができます。保存した情報は次回、WARを起動したときに自動的に読み込みます。
- WARへのひとつの制御情報(アクセス条件)を追加します。この条件はロボットに対する指示となります。例えば、指定したURLにあるHTMLファイルを基準として、そこからハイパーリンクされたHTMLファイルや指された画像、音楽データなどを自動で辿る(自動アクセスする)ためのURLを指定することができます。操作はメニューから「自動アクセス開始指示」を選ぶか、「情報指示」ビューにおいてマウスの右クリックで表示されるメニューから「アクセス条件の指定」を選ぶことで条件を指定する画面が表示されます。ここで設定可能な条件は次のとおりです。
- ・自動アクセスするURLの指定
-
- ここで指定されたURLにあるHTMLファイルを基準として、そこからハイパーリンクされたHTMLファイルや指された画像、音楽データなどを自動で辿る(自動アクセスする)ためのものです。先頭の"http://"を記述する必要はありません。ここで指定したURLを入り口として、そのHTMLファイルに含まれるリンクは無限の可能性がありますので、以下の設定も行ってください。
- ・自動アクセスする深さの最大値の指定
-
- 自動アクセスするURLにあるHTMLファイルを基準として、それに含まれるハイパーリンク先がHTMLファイルであったとき、またそのHTMLファイルを基準としてハイパーリンクを辿ることができます。この指定は、これらのハイパーリンクをどこまで辿るかという深さ(レベル)を指定します。この数値を大きくすることで大量のファイルを受け取ることができますが、あまりにも多過ぎる情報のために期待する時間内に全てを取得することができないかも知れません。通常は2〜ひと桁以内の数値が望ましいでしょう。
[注意]同一サイトの情報のみアクセスするチェックボックスにチェックした場合(ドメイン名限定指定をした場合)は、最大256階層まで処理します。チェックした場合は、自動アクセスする深さを1や2にしてもこの値は無効になりますので注意してください。
- ・GIF画像はアクセスしない(チェックボックス)
-
- GIF画像はバナー広告などによく用いられます。このチェックボックスをチェックすることにより、ファイルの拡張子が.GIFであった場合は、この画像ファイルはアクセスしません。従って不要なバナー広告などをISMがキャッシュすることを避けることができます。しかし、必要とするファイルの拡張子がGIFであるものも含まれるような場合、このチェックボックスは外しておいてください。
- ・実行データはアクセスしない(チェックボックス)
-
- 実行データは、悪意プログラムや、ウイルスプログラムである可能性があります。例えば、ダイヤルQ2や、国際電話を勝手にかけるプログラムや、トロイの木馬を含むようなプログラムといったものです。このチェックボックスをチェックすることにより、拡張子が.EXEであった場合は、この実行プログラムファイルにはアクセスしません。従って、悪意プログラムや、ウイルスプログラムなどをISMがキャッシュすることを避けることができます。しかし、必要とするファイルの拡張子がEXEであるような場合(例えば、自動解凍形式のファイルなどと予め分かっている場合)は、このチェックボックスを外しておいてください。
- ・同一サイトの情報のみアクセスする(チェックボックス)
-
- WARは自動アクセスするURLにあるHTMLファイルを基準として、それに含まれるハイパーリンク先がHTMLファイルであったとき、またそのHTMLファイルを基準としてハイパーリンクを辿ることができます。しかし、そのHTMLファイルが指すリンク先が単なる他サイトへのリンクであった場合、これ以降のアクセスは無限に広がるため、収拾がつかなくなる可能性があります。このチェックボックスをチェックすることにより、こういった情報収集の分散問題を避け、同じドメイン(www.test.comなどの)を持つ同一サイトの範囲に限り、アクセスできるようになります。
- ・次のサイトはアクセスしない(チェックボックス)
-
- 自動アクセスするURLにあるHTMLファイルを基準として辿ることによりアクセス可能な範囲で、予め、アクセスが不必要なサイトのURLが分かっている場合、このチェックボックスをチェックし、そのURLを右に入力しておくことで、このサイトにはアクセスしなくなります。例えば、自動アクセスするURLにあるHTMLファイルから複数のドメインに渡ってハイパーリンクがあるが、ある部門だけのドメインは取得する必要がない、といった場合にこの指定が有効となります。
[注意]このチェックボックスを有効にすると、自動アクセスする深さの最大値の指定が無効となり、最大256階層まで処理しますので注意してください。
「指示情報」ビューには「/」や「~」、「#」、「http」で始まらない文字列で表現されます。
- ・次のデータはアクセスしない(チェックボックス)
-
- 自動アクセスするURLにあるHTMLファイルを基準として辿ることによりアクセス可能な範囲で、予め、アクセスが不必要なサイトのデータ(ある固定文字列を含むもの)が分かっている場合、このチェックボックスをチェックし、その固定文字列を右に入力しておくことで、このサイトにはアクセスしなくなります。例えば、bannerという文字を含むデータならば、*banner*と入力します。
「指示情報」ビューには「/」で始まる文字列で表現されます。
- ・次のサイトはアクセスする(チェックボックス)
-
- 上記の指定のうち、「同一サイトのみアクセスする」などの限られた範囲を指定しておいても、予め、アクセスが必要なサイトのURLが分かっている場合、このチェックボックスをチェックし、そのURLを右に入力しておくことで、このサイトにアクセスします。例えば、「同一サイトのみアクセスする」が、このHTMLファイルからハイパーリンクされた新聞社のトップページは取得したい、などの場合にこの指定が有効となります。
「指示情報」ビューには「~」で始まる文字列で表現されます。
- ・次のデータはアクセスする(チェックボックス)
-
- 上記の指定のうち、「実行データはアクセスしない」などの制限を指定しておいても、予め、アクセスが必要なサイトのデータ(ある固定文字列を含むもの)が分かっている場合、このチェックボックスをチェックし、その固定文字列を右に入力しておくことで、このサイトにアクセスします。例えば、「実行データはアクセスしない」が、SAMPLE.EXEというファイルだけは取得したい、などの場合にこの指定が有効となります。
「指示情報」ビューには「~/」で始まる文字列で表現されます。
- (2)開始
-
- WARに対して設定したアクセス条件(コマンドファイルの実行)を開始する指示です。WARは「開始」指示を受けると、アクセス条件(URL、リンクの深さ、ファイル拡張子など)に従って、ISMを経由してインターネットにアクセスを行い、必要なファイルを取得してきます。ローカルのディスク上にはISMがキャッシュします。
アクセス中は画面右半分の「表示状態」ビューにアクセス中のURLやアクセスの結果、状況などを表示します。
アクセスが完了した場合は「表示状態」ビューの結果欄に「完了」メッセージを表示します。
-
- 「停止指示」
-
- 自動アクセスしているWARに対する停止の指示ができます。
-
- (1)区切りの良いところで停止
-
- 自動アクセスしているWARに対する停止の指示ができます。WARが自動アクセスしている最中は、インターネットへのアクセスを行うと同時に、ローカルに保存しようとしているキャッシュファイルのオープンを行ったままです。強制的に停止するとローカルのファイルが壊れる可能性があるため、ファイル単位でのアクセスが終わった区切りの良い時点で自動アクセスを停止させます。
-
- 「プログラム情報」
-
- ISMに関する次の情報を表示します。
-
- 「ヘルプ」
-
- WARのヘルプです。
WAR.INIファイルは、WARの実行環境を定義するファイルです。WARを動作させるためには、画面メニューからの設定に加え、WARプログラム(WebAccessRobot.exe)と同じディレクトリに存在する「WAR.INI」ファイルをエディタなどで直接編集する方法があります。画面のメニューからではなく、このWAR.INIを直接編集する場合は、必ずプログラムを終了させたあと設定の変更を行い、プログラムを起動してください。設定は以下を参考にしてください。
-
- 注意:
- WAR.INIファイルは、WARプログラムと同じディレクトリ中に存在しなければなりません。
- WAR.INIファイルで指定した実行環境の幾つかは、WAR実行中に、WARの画面のメニューを用いて、変更することができます。
- WARは、実行終了時や、実行環境が変更された時、WAR.INIファイルを作り直して、新しい実行環境を保存します。
WAR.INIファイルで使うことのできるステートメントと指定値と意味は、以下の通りです。
-
- [WebAccessRobot]
-
- WARの設定ファイルであることを示すコメントです。変更することはできません。
-
- commandfile=
-
- WARの現在の制御情報(アクセス条件)を保存するコマンドファイルを指定します。省略すると、WARと同じディレクトリの中にある「robotcommand.txt」ファイルが指定されたものと見なします。コマンドファイルについては、コマンドファイルについてを参照してください。規定値は「robotcommand.txt」です。
-
- OriginalDataDir=
-
- WARを「Webページ改ざんチェックモード」で、動作させる場合、改ざんチェックの基準データの場所をディレクトリ名で指定します。改ざんチェックの基準データの場所が指定されていないのに「Webページ改ざんチェックモード」指定(#mode=tampercheck指定)を行った場合、その指定は無視されます。規定値は「d:\」です。
-
- LogBaseDir=
-
- WARのロギングを取得するための基本となるディレクトリを設定します。規定値はありませんが、指定を省略すると、WARと同じディレクトリになります。
-
- ■コマンドファイル(...)が見つかりません。
-
- WARに指示を出すためのコマンドファイルが設定されていません。WAR.INIファイルの「commandfile」には規定値では「robotcommand.txt」が設定されています。特に変更しない場合は、WARのメニューからアクセス条件の指定などを行って、コマンドファイルを作成してください。WAR.INIファイルについてはWAR.INIの設定を参照してください。
-
- ■改ざんチェックで用いる基準データのフォルダ(...)が見つかりません。
-
- WAR.INIファイルの「OriginalDataDir」の設定を正しく設定してください。この設定は、・・・のディレクトリ場所を指定します。例えば c:\war\data を指定する場合は「OriginalDataDir=c:/war/data」または「OriginalDataDir=c:\war\data」となります。WAR.INIファイルについてはWAR.INIの設定を参照してください。
-
- ■インターネットスマートマネージャ(ISM)が起動されていないか、ポート番号が7000になっていません。
-
- WARはISMを介してインターネットにアクセスします。ISMを起動していない場合は、ISM(InternetSmartManager.exe)を起動してください。既に起動している場合は、ポート番号が7000でない可能性があります。ISM.INIファイルの「ISM_PORT_NO=」ステートメントが7000であることをエディタなどで確認してください。
-
- ■全受信指示完了しましたが、異常終了したものがあります。
-
- このメッセージは「状態表示」ビューに表示されます。ロボットに対する指示(アクセス条件)に基づき、インターネット上のWebサイトにアクセスし、全ての指示を完了しました。しかし、アクセスの途中で何らかのエラーが発生しているために、ユーザが期待するファイルが全て取得できていない可能性があります。エラーについては「状態表示」ビューの時刻を過去にトレースし、赤い文字で表示されたエラーの結果を確認してください。原因としては、Webサイト側にある場合(例えばHTMLのリンクが切れている場合、ファイルが存在しない場合、ネットが混雑しているため受け取れない場合、その他ネット上の異常)や、ユーザミス(ISMが起動されていない場合、ロボットに対する指示であるアクセス条件に存在しないURLを指定している場合、ネット回線の異常)などが考えられます。「状態表示」ビューにおいて、アクセス開始した時刻から終了するまでの状況や結果を確認して、全てにエラーが発生している場合はユーザミスの可能性があります。幾つかのアクセスが成功している(実際にネットワークにアクセスできている)ならば、Webサイト側に原因がある可能性がありますので、Webブラウザなどでアクセスできるかどうか確認してみてください。
-
- ■受信が途中で異常終了し、0しか受信できませんでした。
-
- このメッセージは「状態表示」ビューに表示されます。原因や対策については「全受信指示完了しましたが、異常終了したものがあります。」を参考にしてください。
-
- ■自動アクセスする深さを1や2にしても、数階層下まで取得してしまう。
-
- 同一サイトの情報のみアクセスするチェックボックスに有効にした場合(ドメイン名限定指定をした場合)は、最大256階層まで処理します。このチェックボックスを有効にした場合は、自動アクセスする深さを1や2にしてもこの値は無効になりますので注意してください。
-
- ■リンクを自動調整しても正しくリンクできません。
-
- リンクする全てのファイルをWebサイトからキャッシュしていないか、自動調整するファイルのチェックボックスを付けずに自動調整したことなどが考えられます。WARやWebブラウザからISMを介して必要なファイルを全てキャッシュするか、自動調整するファイルには全てチェックしてください。あるいは、全てのファイルをキャッシュしていて、WPMが自動調整したにも関わらず、ローカルのファイルをWebブラウザで表示させてリンクできないような場合は、以下のようなケースが考えられます。現バージョンのWPMではこれらのリンクについて自動調整することをサポートしておりません。
- CGIなどのプログラムを実行するようなリンクの場合
- JavaScriptなどの組み込みプログラムを実行するリンクの場合
- ヘッダにBASEリファレンスし、相対リンクがあるHTMLの場合
- あるディレクトリの中で、ファイル名とディレクトリ名が同一だった場合
-
- ■HTMLソースを表示させると文字化けする。
-
- HTMLソースの文字コードとWindowsの2バイト系(漢字)の文字コードが一致していないためです。例えばUNIXのWebサーバにおいてHTMLファイルにEUCコードが使われている場合、ISMがキャッシュしたファイルはEUCになったままですが、WindowsはShift-JISコードですので2バイト系の漢字が文字化けします。但し、WPMにおけるハイパーリンクの自動調整機能は1バイト文字の<a href〜>タグを認識しますので、文字コードが異なっても自動調整機能には問題ありません。また、Webブラウザは文字コードを変換して表示する機能を持っていますので、WPMで自動調整したファイル自体が文字化けしていても、正常に表示されます。もし、Webブラウザにおいても文字化けするようでしたら、Webブラウザの表示文字コードを変更してください。
-
- ■一つもチェックがありません。
-
- 複写や自動調整などの処理の指示があったにも関わらず、その処理対象となるファイルが選択されていません。「ディレクトリの階層表示」ビューから、処理対象とするファイルの左にあるチェックボックス(□)をマウスでクリックして選択してください。
-
- ・ISM
-
- インターネットスマートマネージャ(InternetSmartManager.exe)のこと。
-
- ・WAR
-
- Webアクセスロボット(WebAccessRobot.exe)のこと。
-
- ・WPM
-
- Webプレゼンテーションメーカー(WebPresentationMaker.exe)のこと。
-
- ・クッキー
-
- クッキーは、Netscape Communications社が、開発した技術で、利用者のコンピュータ上に情報の小片を置いておき、ウェブにアクセスするときそれを、サーバ側が、認識することで、例えば、訪問履歴等を知り、利用者に対する木目細かなサービスを実現すること を狙いとするものです。
-
- ・リファラー
-
- HTTPアクセスメソッドのヘッダーに含まれるリファラーは、あるWebページをアクセスしたとき、直前にどのWebページを見ていたかをサーバに知らせるために使われています。
-
- ・PUTメソッド
-
- PUTメソッドは、HTTPアクセスメソッドの一種で、利用者のコンピュータからサーバに、データを渡す為の手段の一つです。PUTメソッドを用いることにより、利用者が、サーバに色々な要求を行ったり、サーバが、利用者から情報を収集したりすることが可能となります。サーバは、住所、氏名等の個人情報をPOSTメソッドやPUTメソッドを用いて収集することがあります。この為、ISMのプライバシー保護機能の「POSTメソッドとPUTメソッドとの禁止機能」を設定すると、POSTメソッドとPUTメソッドとを用いたウェブアクセスを拒否することができます。
-
- ・CGI
-
- CGIとは「Common Gateway Interface」の略で、Webサーバでプログラムを実行させて、その結果を表示させる 仕組みのことです。CGIを用いることにより、ブラウザの表示画面のフォーム形式などから入力した情報を、ウェブサーバーに送り出し、掲示板やアクセスカウンターや訪問者リストなどを作ることができます。
-
- ・SSL
-
- SSLとは「Secure Socket Layer」の略で、WebブラウザとWebサーバ間で安全な通信を行なうためにWebサーバとWebブラウザの間の通信を暗号化するものです。インターネット上でプライバシー情報やキャッシュカードのデータなどに関する情報を安全に通信するために考案されたものです。
インデックスに戻る